 当前位置:
当前位置:服务热线
0755-83647532

发表日期:2019-07-19 文章编辑: 阅读次数:
2017 年 11 月 7 日,加州大学伯克利分校、德克萨斯大学和加州大学戴维斯分校的研究人员发表了他们的研究结果:在 CPU 上 31 分钟(截至发表时间)训练完 ResNet-50* 以及 11 分钟训练完 AlexNet*,使其达到一流的准确性,创造了纪录。这些结果均在英特尔® 至强® 可扩展处理器(之前代号为 Skylake-SP)上实现。其中影响性能速度的主要因素包括:
1、英特尔至强可扩展处理器的计算和内存容量
2、面向深度神经网络的英特尔® 数学核心函数库(英特尔® MKL-DNN)和常用深度学习框架中的软件优化
3、面向监督式深度学习工作负载的分布式训练算法的最新技术成果
这种性能水平说明,英特尔至强处理器是实施深度学习训练的理想硬件平台。数据科学家现在可以采用现有的通用英特尔至强处理器集群执行深度学习训练,并继续将其用于深度学习推理、经典机器学习和大数据工作负载。他们可以使用 1 个服务器节点实现卓越的深度学习训练性能,并使用更多服务器节点以近线性的方式扩展至数百个节点,进一步缩短训练时间。
本文由 4 个部分组成,主要探讨帮助实现创纪录的训练速度的三个主要因素,并提供多个使用英特尔至强处理器实施深度学习训练的商业用例。虽然本文主要介绍训练性能的提升,但前两个因素也会显著提升推理性能。
第 1 部分:英特尔至强可扩展处理器的计算和内存容量
训练深度学习模型通常需要大量的计算。例如,训练 ResNet-50 总共需要完成一千兆兆次 (1018) 单精度运算。支持高计算吞吐量的硬件如果能够实现较高的利用率,可大幅缩短训练时间。高利用率要求较高的带宽内存和巧妙的内存管理,以使芯片保持繁忙的计算状态。新一代英特尔至强处理器具备以下特性:大量处理器频率较高的内核、高速系统内存、大量每内核中级高速缓存(MLC 或 L2 高速缓存),以及新 SIMD 指令,因此新一代英特尔至强处理器是训练深度学习模型的理想平台。在第 1 部分中,我们将回顾英特尔至强可扩展处理器的主要硬件特性,包括计算和内存,并对比英特尔至强可扩展处理器与前代英特尔至强处理器运行深度学习工作负载的性能。
2017 年 7 月,英特尔推出了基于 14 纳米制程技术构建的英特尔至强可扩展处理器家族。英特尔至强可扩展处理器支持每路(多达 8 路)28 个物理内核(56 线程),处理器基础频率为 2.50 GHz,最大睿频频率为 3.80 Ghz,并支持 6 条内存通道和高达 1.5 TB 2,666 MHz DDR4 内存。最高端的英特尔至强铂金 8180 处理器可在双路系统上提供高达 199GB/秒的 STREAM Triad 性能a,b。至于插槽内数据传输,英特尔至强可扩展处理器推出了全新的超级通道互联 (UPI) 技术,这种一致性互联技术可取代快速通道互联 (QPI) 并将数据速率增至每 UPI 端口 10.4 GT/秒以及双路配置下多达 3 个 UPI 端口。
其他改进包括 38.5 MB 共享非包含式末级高速缓存(LLC 或 L3 高速缓存),即内存读取直接填充至 L2,而非 L2 和 L3,以及每内核 1MB 专有 L2 高速缓存。英特尔至强可扩展处理器内核目前包含 512 位宽融合乘加 (FMA) 指令作为大型 512 位宽矢量引擎的一部分,以及每内核 2 个并行计算的 512 位 FAM 单元(之前由英特尔至强融核™ 处理器产品线推出)1。相比前代英特尔至强处理器 v3 和 v4(之前代号分别为 Haswell 和 Broadwell)的 256 位宽 AVX2 指令,这种 FMA 指令能够显著提升性能,支持训练和推理工作负载。
英特尔至强铂金 8180 处理器支持每路高达 3.57 TFLOPS (FP32) 和 5.18 TOPS (INT8)2。512 位宽 FMA 可将英特尔至强可扩展处理器提供的 FLOPS 增加一倍,并显著加快单精度矩阵算法的速度。对比 SGEMM 和 IGEMM 性能,我们发现,相比前代英特尔至强处理器 v4,性能分别提升了 2.3 倍和 3.4 倍c,e。相比整个深度学习模型上的性能,我们发现,将英特尔® neon™ 框架用于 ResNet-18 模型,使用 FP32 时的训练和推理吞吐量相比前代英特尔至强处理器 v4 分别提升了 2.2 倍和 2.4 倍d,f。
第 2 部分:英特尔 MKL-DNN 和主要框架中的软件优化
软件优化对实现较高的计算利用率和性能提升至关重要。英特尔优化的 Caffe*(有时称为英特尔 Caffe)、TensorFlow*、Apache* MXNet* 和英特尔 neon 均面向训练和推理优化。Caffe2*、CNTK*、PyTorch* 和 PaddlePaddle* 等其他框架的优化也正在进行中。在第 2 部分,我们将英特尔优化和未经英特尔优化的模型的性能进行了对比;介绍英特尔 MKL-DNN 库如何帮助实现较高的计算利用率;探讨英特尔 MKL 与英特尔 MKL-DNN 之间的区别;还将介绍为了进一步提升性能在框架层所进行的其他优化。
两年前,由于软件优化有限且计算利用率较低,英特尔® 处理器上的深度学习性能并未达到最佳。深度学习科学家误以为 CPU 不适合运行深度学习工作负载。两年来,英特尔一致努力优化深度学习函数,以实现较高的利用率,支持深度学习科学家使用现有通用英特尔处理器实施深度学习训练。通过构建常用深度学习框架(该框架将自动默认下载和构建英特尔 MKL-DNN)时设置配置标记,数据科学家可充分利用英特尔 CPU 优化。
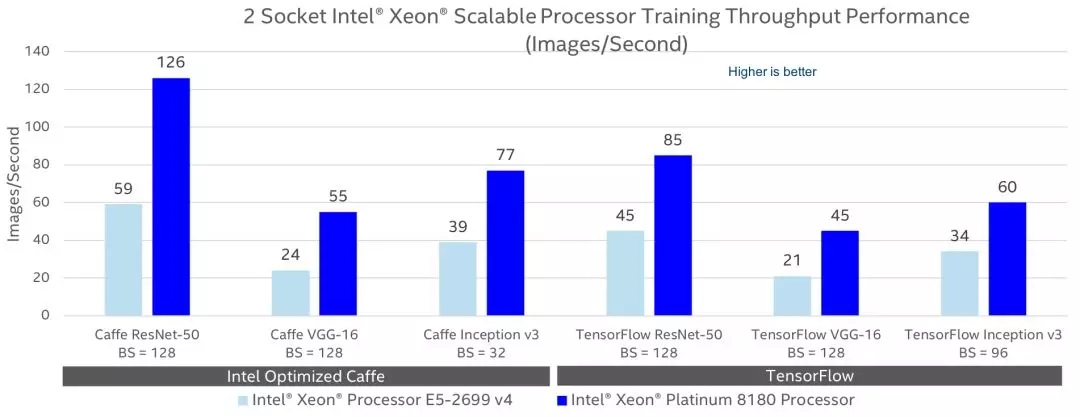
英特尔至强处理器与英特尔 MKL-DNN 相结合,可将性能提升超过 100 倍。例如,借助英特尔至强处理器 E5-2666 v3 上的 Apache MXNet(c4.8xlarge AWS* EC2* 实例)在 AlexNet*、GoogleNet* v1、ResNet-50* 和 GoogleNet v3 上跨所有可用 CPU 内核执行的推理分别实现了 111 倍、109 倍、66 倍和 92 倍的吞吐量提升。基于英特尔至强处理器 E5-2699 v4 上的 Caffe2 在 AlexNet 上跨所有 CPU 内核进行的推理实现了 39 倍的吞吐量提升。借助英特尔至强处理器 E5-2699 v4 上的 TensorFlow 训练 AlexNet、GoogleNet 和 VGG* 分别实现了 17 倍、6.7 倍和 40 倍的吞吐量提升。借助英特尔至强可扩展铂金 8180 处理器上的英特尔优化的 Caffe 和英特尔 MKL-DNN 跨所有 CPU 内核训练 AlexNet,相比未借助英特尔至强处理器 E5-2699 v3 上的英特尔 MKL-DNN 的 BVLC*-Caffe,吞吐量提升了 113 倍d,g。图 1 和图 2 对比了英特尔至强处理器 E5-2699 v4 和英特尔可扩展铂金 8180 处理器采用面向 TensorFlow 和英特尔优化的 Caffe 的英特尔 MKL-DNN 库时的训练和推理吞吐量。这些框架和其他框架的性能预计将随着进一步的优化而得以提升。所有这些数据都使用 fp32 精度计算得出。我们将稍后添加数值精度较低的数据;低精度可提升性能。

这些优化的核心是英特尔® 数学核心函数库(Intel® MKL)以及英特尔 MKL-DNN 库。深度学习模型有很多种,而且看起来有很大的不同。但大多数模型都通过有限的构建模块(称为基于张量运行的基元)而构建。其中部分基元包括内积、卷积、修正线性单元或 ReLU、批处理标准化等,以及操纵张量所需的函数。这些构建模块或低级深度学习函数已面向英特尔 MKL 库中的英特尔至强产品家族进行了优化。英特尔 MKL 库包含许多数学函数,其中一部分可用于深度学习。为了有针对性更强的深度学习库,并与深度学习开发人员协作,英特尔在 Apache 2 许可下发布了英特尔 MKL-DNN,其中包含构建复杂模型所需的所有关键构建模块。英特尔 MKL-DNN 支持行业和学术型深度学习开发人员分配这些库,并提供新函数或改进后的函数。英特尔 MKL-DNN 预计在性能方面处于领先地位,因为所有最新优化都将率先用于英特尔 MKL-DNN。
深度学习基元在英特尔 MKL-DNN 库中通过结合预取、数据布局、缓存模块化、数据复用、矢量化和寄存器分块策略,进行了优化。高利用率要求数据可随时用于执行单元 (EU)。这要求在高速缓存中预取数据和复用数据,而不是从主内存中多次提取相同的数据。对缓存模块化来说,目标是最大限度地提高适合高速缓存(通常在 MLC 中)的给定数据块的计算率。数据布局连续安排在内存中,以便最内层循环中的访问尽可能的连续,避免出现不必要的收集/分散操作。这样可以提高缓存行(以及带宽)的利用率,并提高预取程序的性能。循环模块时,我们将模块的外部维度限制为 SIMD 宽度的倍数,并让最内层维度在数组 SIMD 宽度上循环,以支持高效矢量化。为了隐藏 FMA 指令的延迟,可能需要使用寄存器分块3。
其他跨内核并行化对实现高 CPU 利用率非常重要,比如使用 OpenMP* 实现迷你批次的并行化。这要求改进负载均衡,以便每个内核都完成相同的工作量,并减少内核间的同步化事件。均衡、高效地使用所有内核要求给定层内实现额外的并行化。
这些优化可确保所有关键的深度学习基元,比如卷积、矩阵乘法、批处理标准化等,都高效矢量化为最新 SIMD,并跨内核实现并行化。英特尔 MKL-DNN 基元均在 C 中实施,并支持 C 和 C++ API 绑定,以最广泛地应用于深度学习函数:
· 直接批量卷积
· 内积
· 池化:最大、最小、平均
· 标准化:跨通道局部响应归一化 (LRN),批归一化
· 激活:修正线性单元 (ReLU),softmax
· 融合基元:卷积+ReLU
· 数据操作:多维转置(转换)、拆分、合并、求和和缩放
· 即将推出:长短期记忆 (LSTM) 和门控循环单元 (GRU)
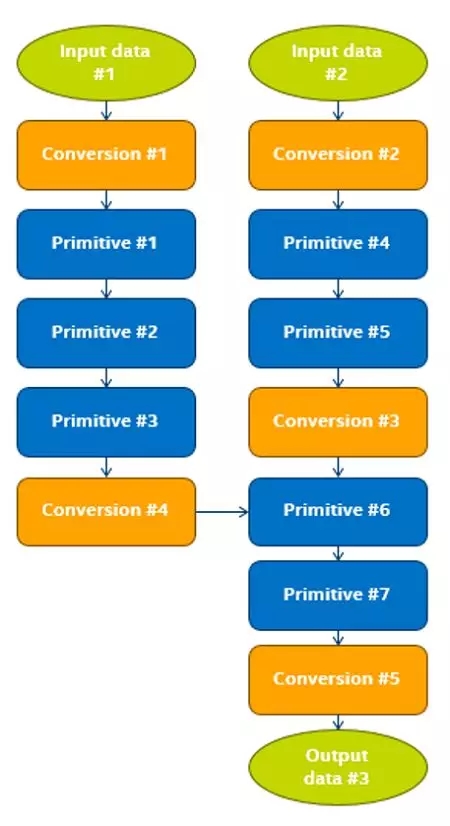
有多种深度学习框架,比如 Caffe、TensorFlow、MXNet、PyTorch 等。框架层的修改(代码重新因子化)要求高效利用英特尔 MKL-DNN 基元。框架小心地用相应的英特尔 MKL-DNN API 取代对现有深度学习函数的调用,以避免框架和英特尔 MKL-DNN 库争用相同的线程。在设置期间,框架管理从框架到 MKL-DNN 的布局转换,并在相应的输出输入数据布局不匹配的情况下分配临时阵列。为了提升性能,可能要求进行图形优化以最大限度地减少不同数据布局之间的转换,如图 3 所示。在执行步骤期间,数据在 BCWH(批处理、通道、宽度、高度)这样的平面布局中馈送到网络中,并转换为适用于 SIMD 的布局。当数据在层之间传播时,数据布局被保留,并在需要执行英特尔 MKL-DNN 不支持的操作时进行转换。
另外,当通过将插槽和内核分区为独立的计算设备并在每个插槽中运行多个实例(每台计算设备一个实例)来执行部分框架和工作负载时,内核利用率将会得到提升。Saletore 等人 介绍了 在不改变框架中任何一行代码的情况下实施此方法的步骤。这些方法可基于现有软件优化,将训练和推理性能分别提升 2 倍和 2.7 倍。
第 3 部分:面向监督式深度学习的分布式训练算法的技术成果
训练大型深度学习模型通常需要耗费几天,甚至几周的时间。将计算要求分布于多个服务器节点可缩短训练时间。但无论使用哪种硬件,都会遇到算法方面的挑战,不过分布式算法近期所取得的进展可解决这些挑战。在第 3 部分中,我们将回顾梯度下降和随机梯度下降 (SGD) 算法,并介绍用大型迷你批次进行训练的局限性;探讨模型和数据并行化;回顾同步 SGD (SSGD)、异步 SGD (ASGD) 和全归约/广播算法;最后展示近期支持大型迷你批次 SSGD 训练并帮助获得显著成效的最新进展。
在监督式深度学习中,输入数据在模型中传递,输出与地面真值或预期输出进行对比。然后计算出惩罚或损失。训练模型涉及调整模型参数以减少这种损失。有各种优化算法可用来最大限度地减少损失函数,比如梯度下降或随机梯度下降、Adagrad、Adadelta、RMSprop、Adam 等变量。
在梯度下降 (GD)(亦称最陡下降)中,由权重集合定义的特定模型的损失函数在整个数据集上计算。权重通过移至梯度的反方向而进行更新;即朝局部最小值移动:更新权重 = 当前权重 – 学习率 * 梯度。
在随机梯度下降 (SGD) 中,更准确地称为迷你批次梯度下降,数据集分为多个迷你批次。损失相对于迷你批次计算,而且权重使用与梯度下降相同的更新原则进行更新。还有许多其他变量,有的通过在与梯度相反的方向积累速度(称为动量)而加快训练过程,有的通过根据梯度的标准自动修改学习率,帮助数据科学家轻松选择合适的学习率。有关这些变量的深入介绍可以在别处找到。
随着迷你批次逐渐增大并在迷你批次大小等于整个数据集时变得相同,SGD 的行为接近 GD 的行为。GD 面临三大挑战(迷你批次很大时 SGD 也面临这三大挑战)。第一,每个步骤或每次迭代的计算成本都很大,因为要求在整个数据集上计算损失。第二,梯度接近零或曲率变化时,鞍点或鞍区附近的学习变慢。第三,根据英特尔和西北大学研究人员的研究,优化空间有多个尖锐最小值。梯度下降不探索优化空间,而是直接移至起点以下的局部最小值,它通常为尖锐最小值。尖锐最小值无法推广。尽管测试数据集的整体损失函数与训练数据集的类似,但尖锐最小值处的实际成本可能大不相同。图 4 形象地展示了这种不同,测试数据集的损失函数稍稍偏移了训练数据集的损失函数。这种变化导致汇合于尖锐最小值的模型产生较高的测试数据集成本,意味着该模型无法进行推广给训练集以外的数据。另一方面,汇合于平坦最小值的模型的测试数据集成本较低,意味着该模型可以推广给训练集以外的数据。

小迷你批次 SGD (SMB-SGD) 可解决这些问题。首先,使用 SMB-SGD 的计算成本不高,因此每次迭代的速度都很快。整个数据集通常进行多次迭代,而 GD 中只执行 1 次。在整个数据集上 SMB-SGD 要求的传递通常较少,因此训练速度更快。第二,使用 SMB-SGD 时鞍点处不太可能出现堵塞情况,因为训练集中部分迷你批次的梯度不可能为零,即使整个训练集都梯度为零。第三,由于 SMB-SGD 能够更好地探索解决空间,而不是直接移至起点以下的局部最小值,因此更能找到平坦最小值。另一方面,极小的迷你批次也不是最佳选择,因为要实现较高的 CPU(或 GPU)利用率很难。将小迷你批次的计算工作负载分布于多个工作节点时,这种问题会变得更加严峻。因此,必须找到足够大的迷你批次,以维持较高的 CPU 利用率,但也不能太大以避免出现 GD 问题。这对下面要讨论的同步数据并行 SGD 来说更加重要。
在多个工作节点中高效分布工作负载,可缩短整体训练时间。所使用的技巧有两种:模型并行化和数据并行化。在模型并行化中,模型在多个节点之间划分,每个节点都处理相同的迷你批次。当内存要求超过 worker 的内存时,模型并行化可用于实践。数据并行化方法更加常用,最适合权重较少的模型。在数据并行化中,迷你批次在工作节点中划分,每个节点都有完整的模型并处理一段迷你批次,称为节点批次。每个工作节点都计算节点批次的梯度。然后通过归约算法聚集这些梯度,以计算整个迷你批次的梯度。然后更新模型权重,更新后的权重被传播至各个工作节点。这也称为归约/传播或仅全归约方案(全归约选项列表将在下文种介绍)。迷你批次的每次迭代或周期结束时,所有工作节点都有相同的更新模型,即节点实现了同步化。这被称为同步 SGD (SSGD)。
异步 SGD (ASGD) 能够消除同步化的开销。但 ASGD 面临其他挑战。ASGD 要求更多地优化超参数(比如动量),并要求更多训练迭代。另外,它不匹配单节点性能,因此调试起来比较困难。在实践中,尚未证明 ASGD 能够在大型模型上进行扩展和保持准确性。斯坦福大学、LBNL 和英特尔研究人员已经证明,ASGD/SSGD 混合方法可以用于节点在多达 8 个组中完成集群化的情况。组内更新是同步的,组之间的更新是异步的。由于 ASGD 所面临的挑战,超过 8 个组会使性能降低。
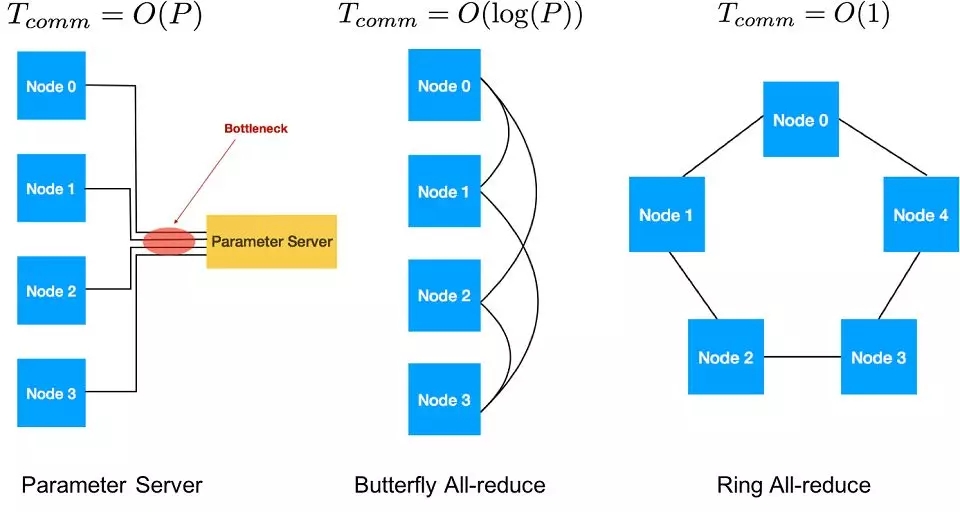
其中一种用于传递梯度的策略是,将一个节点指定为参数服务器,计算节点梯度的总和、更新模型,并将更新权重发送回各个 worker。但使用一个参数服务器收发所有梯度会存在瓶颈。除非使用 ASGD,否则不建议采用参数服务器策略。
全归约和传播算法用于传递和添加节点梯度,然后传播更新权重。有各种全归约算法,包括 Tree、Butterfly 和 Ring。Butterfly 是 O(log(P)) 迭代时进行延迟扩展的最佳选择,其中 P 代表工作节点的数量,并结合了 reduce-scat 和广播。Ring 是带宽的最佳选择;对大型数据通信来说,它可以通过节点数量在 O(1) 处进行扩展。在带宽受限的集群中,AllReduce Ring 算法通常更加适用。有关 AllReduce Ring 算法的详细介绍可在 别处找到。 图 5 显示了各种通信策略。
2014 年 11 月,Jeff Dean 谈到了 谷歌将训练时间从 6 周缩短至 1 天的研究目标。三年后,使用 CPU 可在 11 分钟内训练完 AlexNet。这是通过使用较大的迷你批次来实现的,这种迷你批次支持将计算工作负载分布至超过 1000 个节点。为了高效扩展,梯度通信和更新权重必须隐藏在梯度计算中。
可使用以下技巧增加整体迷你批次的规模:1) 按比例增加迷你批次的规模和学习率;2) 在训练的最初部分慢慢提高学习率(称为热身学习率);3) 使用层自适应率缩放 (layer-wise adaptive rate scaling (LARS)) 算法使模型的各层拥有不同的学习率。下面我们来详细了解每一种技巧。
迷你批次越大,梯度中的置信度越高,因此可使用的学习率也越大。作为一条经验法则,学习率随着迷你批次大小的增加而按比例增加4。这项技巧支持加州大学伯克利分校的研究人员使用 GoogleNet 模型,将迷你批次的大小从 256 增至 1024,并扩展至 128 个 K20-GPU 节点,将训练时间从 21 天缩短至 10.5 小时,英特尔研究人员使用 VGG-A 模型,将迷你批次大小从 128 增加至 512,并扩展至 128 个英特尔至强处理器 E5-2698 v3 节点。
较大的学习率可能导致出现分散(损失随迭代而增加,而非降低),尤其在初始训练阶段。这是因为在初始训练阶段,梯度范数大于权重范数。通过在初始训练阶段(例如在前 5 个 epoch 中)逐渐增加学习率可缓解这种情况,直到最后达到目标学习率。这种技巧支持 Facebook* 使用 ResNet-50,将迷你批次大小从 256 增至 8094,并扩展至 256 个 Nvidia* Tesla* P100-GPU 节点,将训练时间从 29 个小时(使用 8 颗 P100-GPU)缩短至 1 小时。这种技巧也 支持 SurfSARA 和英特尔研究人员扩展至 512 颗双路英特尔至强铂金处理器,将 ResNet-50 训练时间缩短至 44 分钟。
NVidia 的研究人员发现,在模型的各个层中,梯度与权重的比例各不相同。他们建议为各个层设置与该比例成反比的学习率。这种技巧(结合上述几种技巧)支持他们将迷你批次的大小增加至 32K。
加州大学伯克利分校、德克萨斯大学和加州大学戴维斯分校的研究人员使用这些技巧刷新了训练时间(截至 2017 年 11 月 7 日发稿时间)的记录:在英特尔 CPU 上 11 分钟训练完 AlexNet*以及 31 分钟训练完 ResNet-50*,使其达到一流的准确性。 他们分别使用 1024 和 1600 台采用英特尔 MKL-DNN 库和英特尔优化的 Caffe 框架5的双路英特尔至强铂金 8160 处理器服务器。
许多数据中心没有高带宽互联或数千个节点。尽管如此,ResNet-50 仍然可以使用 10 Gbps 以太网完美地线性扩展至 32 台,并 99.8% 地扩展至 62 台双路英特尔至强金牌 6148 处理器服务器i。运用这 64 台服务器在 90 个 epoch 中达到预期 75.9% 位列第一的验证准确性,所用的总训练时间是 7.3 小时。
第 4 部分:商业 CPU 用例
额外的计算和内存容量,加上软件优化和分布式训练的进展,有利于行业采用现有英特尔至强处理器进行深度学习。在第 4 部分中,我们将介绍英特尔组装和测试工厂、Facebook* 服务、deepsense.ai* 强化学习 (RL) 算法、京都大学药物设计、Amazon* Web Services (AWS*) 分布式机器学习应用、克莱姆森* 大学自然语言处理、通用电气* 医疗集团医疗成像、爱尔* 眼科医院集团和 MedImaging* Integrated Solutions 糖尿病性视网膜病变、OpenAI* 进化策略 和各种使用 BigDL 的 Apache* Spark* 平台中的几个商业用例 。
英特尔组装和测试工厂获益于英特尔至强处理器上的英特尔优化的 Caffe,改进了芯片制造包装故障检测。该项目旨在降低最终检查点包装表面损坏的人工审查率,同时将假阴性率保持在与人工审查率相同的水平。输入是一组包装照片,目标是对每张照片执行二进制分类,指示每个包装是被拒绝还是通过。他们对 GoogleNet 模型进行了修改以完成此项任务。使用 8 颗连接 10 Gb 以太网的英特尔至强铂金 8180 处理器,在 1 小时内完成了训练。假阴性率始终符合预期的人工准确性。自动完成这一流程为检查员节省了 70% 的时间。
Facebook 利用 英特尔处理器进行推理,并利用 CPU 和 GPU 训练将用于服务中的机器学习算法。训练的频率比推理低得多。推理阶段每天运行数十万亿次,而且通常需要实时执行。部分使用机器学习的重要服务包括新闻推送、广告、搜索、Sigma(异常检测)、Lumos(特征提取器)、Facer(面部识别)、语言翻译和语音识别。新闻推送和 Sigma 在 CPU 上训练,而 Facer 和搜索算法在 CPU 和 GPU 上训练。
deepsense.ai 采用 英特尔处理器进行强化学习。他们训练代理,在 64 颗 12 核英特尔 CPU 上播放各种 Atari 2600 游戏,有时游戏只需短短 20 分钟就可实现完美地线性扩展(注:本文未指定所使用的特定英特尔处理器或互连)。
京都大学研究人员在英特尔处理器上使用深度学习预测基于化合物的相互作用,这是药物设计中的一个重要步骤。对这种深度学习工作负载,他们 声称 that "英特尔 Haswell-EP(采用 128 GB 内存的 E5-2699v3×2)结合 Theano*,在性能和最大支持数据量两个方面,表现都优于 Nvidia Tesla(Ivy Bridge 托管的 K40)。请注意,英特尔至强 E5-2699v3 处理器和 Nvidia Tesla K40 均为前代 CPU 和 GPU。
英特尔与合作伙伴使用 Faster-RCNN* 和英特尔优化的 Caffe 成功地执行了太阳能电池板缺陷检测任务。训练中使用了 300 张增强了 36 度旋转的原始太阳能电池板图片。在英特尔至强铂金 8180 处理器上进行的训练耗费了 6 个小时,在部分不利环境因素的影响下检测准确性达到了 96.3%。推理性能为每秒 188 张图片。这种通用解决方案可用于市场上的各种检测服务,包括石油与天然气检测、管道渗漏和泄露、公共设施检查、输电线路和变电站,以及紧急危机响应。
Amazon Web Services (AWS) GM Matt Wood 报道 ,AWS 和英特尔在 AWS EC2 C5 实例上借助最新版英特尔 MKL 和可用的英特尔至强可扩展处理器优化深度学习,将推理性能提升了 100 倍,并开发可在 AWS 上轻松构建分布式深度学习应用的工具。Wood 解释说:“例如,Novartis 使用 10,600 个 EC2 实例和大约 87000 个计算内核,在短短 9 个小时内完成了需耗时 39 年的化学计算;对照癌症靶标扫描 1000 万种化合物。这种显著的提升将不断改变着各行业的无限可能,例如医疗、生命科学、金融服务、科学研究、航天航空、自动化、制造业和能源。”
克莱姆森大学的研究人员在英特尔处理器上 应用 1.1M AWS EC2 vCPU 研究主题建模,它是自然语言处理的重要组成部分。他们通过近 50 万例主题建模试验,研究计算机如何处理人类语言。主题模型可用于发现文档集合中存在的主题。
通用电气* 医疗集团应用英特尔至强 E5-2650v4 处理器运行通用电气的深度学习 CT 成像分类推理工作负载。他们使用英特尔的深度学习部署工具套件(英特尔 DLDT)和英特尔 MKL-DNN 将吞吐量平均提高了 14 倍(相比基准版解决方案),并将通用电气在仅 4 个内核上实现的吞吐量目标提高了 6 倍。英特尔 DLDT 可提供统一的 API 来集成推理和应用逻辑,从而帮助部署深度学习解决方案。 这些发现为开启智能医疗成像新时代铺平了道路。
爱尔眼科医院集团和 MedImaging* Integrated Solutions (MiiS) 采用 英特尔至强可扩展处理器和英特尔优化的 Caffe 开发深度学习解决方案,以改进针对糖尿病视网膜病变和年龄相关性黄斑变性的筛查。中国政府计划采用该解决方案在全国各地的诊所和小型医院进行高质量的眼部健康筛查。MiiS 首席执行官 Stefan Zheng 说:“英特尔的专业知识、全新的英特尔至强可扩展处理器和面向英特尔架构优化的 Caffe 相结合,取得了令人惊叹的成效,我们正在借助英特尔至强铜牌处理器和英特尔优化的 Caffe 框架稳步前进。”爱尔眼科健康集团总经理 Xu Ming 说:“通过支持我们的诊所提供快速、准确的眼部健康筛查,爱尔眼科可帮助解决眼科医生短缺的问题,为农村地区只能通过乡村诊所看病的人们提供高质量的医疗服务。即使在大城市,我们也可以帮助眼部护理专业人员节省时间,让他们能够专注于治疗病情更严重的患者。我们通过早期检测,提供早期诊断和治疗的机会,帮助保护视力。”
OpenAI 使用 CPU 训练进化策略 (ES),在 RL 性能指标评测 (Atari/MuJoCo) 中实现了强劲的性能。通过使用由 80 台机器和 1,440 个 CPU 内核组成的集群,OpenAI 工程师能够在 10 分钟内训练 3D MuJoCo 人体辅助行走器。
BigDL 是英特尔开源分布式深度学习框架,可为 Apache Spark 提供全面的深度学习算法支持。基于高度可扩展的 Apache* Spark* 平台构建,BigDL 可轻松横向扩展至数百或数千台服务器。此外,BigDL 还集成了英特尔 MKL 和并行计算技术,以在英特尔至强处理器服务器上实现极高的性能。由于在基于至强的 Hadoop*/Spark 集群上运行 BigDL 可提供诸多优势,比如简单性、可扩展性、低总体拥有成本等,BigDL 在业界和开发人员社区中得到了广泛的应用。读者可以参考详细的教程,了解如何将 BigDL 部署于谷歌* 云平台、 AWS* EMR*、Microsoft* Azure* Marketplace、 Microsoft Azure HDInsight、Microsoft 数据科学虚拟机、阿里巴巴* 云 E-MapReduce、Databricks*、Cray* Urika-XC* 分析软件、Cloudera* 数据科学工作台等。
中国银联实施神经网络风险控制系统,该系统使用英特尔至强处理器运行 BigDL 和 Apache Spark。该网络利用 10 TB 训练数据和 100 亿个训练样本。该模型在 32 个英特尔至强处理器节点上训练 ,而且相比传统基于规则的风险控制系统,该模型将风险检测的准确性提高了 60%。
JD.com* 和英特尔团队共同合作,在 BigDL 和 Apache Spark 上使用 SSD 和 DeepBit 模型构建大规模图像特征提取管道。在此用例中,BigDL 为各种深度学习模型(比如对象检测、分类等)提供支持。此外,它还支持复用 Caffe、Torch* 和 TensorFlow 的预先训练的模型。整个应用管道经过全面优化,可在基于英特尔至强处理器的 Hadoop 集群上提供显著加速的性能,相比在 20 个 K40 GPU 卡上运行的相同解决方案,速度提高了约 3.83 倍。
MLSListings* 也和英特尔团队合作,在 Microsoft Azure 的基于英特尔至强处理器的 BigDL 中构建基于图像相似性的房屋推荐系统。他们使用 Places365* 数据集对 GoogleNet v1 和 VGG-16 进行微调,以生成用于计算图像相似性的图像嵌入。
Gigaspace* 已将 BigDL 集成至 Gigapsace 的 InsightEdge* 平台。Gigaspace 构建了一个系统,能在英特尔至强处理器上的 BigDL 中使用训练的自然语言处理 (NLP) 模型,自动将用户请求路由至呼叫中心内相应的专家。
Open Telefónica* Cloud 可提供 Map Reduce Service (MRS),BigDL 在其顶部运行。有关如何使用支持 BigDL 的平台运行深度学习工作负载的步骤,请单击此处。
结论
最新英特尔至强可扩展处理器和英特尔 MKL-DNN 库中优化的深度学习函数可为运行深度学习工作负载(推理、经典机器学习和其他人工智能算法除外)提供充足的计算能力。目前,常用的深度学习框架都集成了这些优化,在有些用例中,单服务器提供的有效性能提升了超过 100 倍。分布式算法所取得的最新进展也支持使用数百台服务器将训练时间从几周缩短至几分钟。数据科学家现在可以采用现有的通用英特尔至强处理器集群执行深度学习训练,并继续将其用于深度学习推理、经典机器学习和大数据工作负载。他们可以使用 1 颗英特尔 CPU 实现卓越的深度学习训练性能,并使用多个 CPU 节点以近线性的方式扩展至数百个节点,进一步缩短训练时间。
文章摘自英特尔开发人员专区
想购买及了解最新英特尔产品,欢迎咨询以下联系方式!
永信贵宾会集团联系方式
咨询热线:0755-82964380
永信贵宾会官网:www.yyhsjs.com
客户垂询邮箱:xinyuan.guo@yyhsjs.com
客户垂询QQ:1953700525
地址:深圳市福田区深南大道1006号国际创新中心C座11楼
邮编:518026


 粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |
粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |